
For an image to be, does an agent have to observe and process it?
Computational Images
The Specter of Representation
“Everything we see hides
another thing, we always want to see what is hidden by what we see. There is an
interest in that which is hidden and which the visible does not show us. This
interest can take the form of a quite intense feeling, a sort of conflict, one
might say, between the visible that is hidden and the visible that is present.”
René Magritte, interview response to his self-portrait painting Son of Man (1964)
The processes of computation and automation that produce digitized images have displaced the concept of an image once conceived through optical devices such as a photographic plate or a camera mirror that were invented to accommodate the human eye. Computational images exist as information within networks mediated by coded machines. They are increasingly less about what art history understands as representation or photography considers indexing and more an operational product of data processing determined by numerical information. Within this new reality, artificial intelligence (AI) applications are rapidly burgeoning as dominant sources of image production. What becomes of a visual world mediated first by data points from a specific training set expressed through tokens, pixels, text?
In this performative website, an extension of my PhD project, I take images as objects to help me think about the philosophy of computation. My account includes a history that is not intended to be exhaustive in the way a historian might undertake, but rather to serve as a theoretical framework that problematizes the political, social, and epistemic causes and effects of computation on the concepts of representation and truth. In the pursuit of such a multidisciplinary analysis, my approach melds theory with practice to serve as investigation of the past, critique of the present, and radical speculation for futurity. If this approach retains anything from the history of philosophy, it is the spirit of askēsis, an exercise in knowing and becoming myself in the activity of thought. The double bind of critically analyzing representation requires the accounting of oneself in the act, thus the process is always both reflective and self-reflective at the same time. In this context, my analysis takes the form of a neural network, linking ideas, histories, names, and objects in multiple dimensions that can be read in multiple ways. Here, the speculative character of this project is intended to function like a database, affording the reader the chance to draw their own connections and to provoke the forming of new lines for what is possible.
link to dissertation: here
interstices of AI 1, 2023. Video made by interpolating between digital photographs taken by me, using Runway ML’s frame interpolation tool. Track Chahargah I, Op.75 by Ata Ebtekar
What is an image?
Post-Image
On a specific theory of images, I follow W.J.T Mitchell in distinguishing between picture and image. Where pictures are concrete objects, images are virtual and phenomenal appearances presented to a beholder through objects. “To picture” is a deliberate act of visual representation, whereas “to image or imagine” is more elusory, general, and spontaneous.[1] Pictures–and photographs–can be taken, while images are made. I think about what to make of images that are made today, co-constructed by sets of computational logic that test the limits of human representation.
Representation is insufficient as a concept to explain instances when images are made and distributed between machines with either subperceptual or little to no human intervention. Here, I identify the capacity of art to transfigure (transmogrify, transduce) the illegibility of computation and AI into new pathways for experiencing the world by material investigations that gesture towards the possibilities of difference. The open indeterminacy of computation allows for an opportunity to decenter normative ideas of what is defined and counted as human.
Firmly in an epoch of algorithmic culture, where computational agency, intelligence, and creativity are legitimate ideas to ponder, I also want to think about its history and its politico-epistemic effects on images. If we can fight to make this new world fairer and more available, wrestled away from its racialized techno-capital-military influences, it is a fight worth having for a future whose cosmology we can start creating today. The relinquishing of the primacy of the human eye and the acknowledgment of the failures of human exceptionalism allow us to experience the world in new and deeper ways. Like symbiotes or cyborgs, we have adopted new epistemic instruments that produce entirely new worlds in collaboration with computing intelligence. The computational sublime is a particular concept developed as a potential escape from automated surveillance culture.
At its most insidious, I argue that the complete cognitive offloading of imaging and sight to computation (the statistical gaze) leads to second order social consequences that intensify sensory-overload (chaos or arbitrariness or unknowability) and enable abuses of power. By second order I mean consequences that are not the direct goal of technological development but nevertheless part of its outcomes. Two specific consequences I identify are: 1) the ways in which human correspondence with social reality is obfuscated and homogenized by narrow applications of computation, and 2) how the ubiquity of surveillance as an outgrowth of computation is changing the form of power dynamics.
My unit of analysis follows the development of computation and is thus not reducible to one society or individual, although I focus mostly on its Western origin story and implications. When I consider social relations, I mean the interactions among organisms that live and commune together. Human social relations are increasingly complexified by myriad variables that affect how we communicate, think, exchange, and live. I consider the effects of computation within this broader framework of the social, which for me also encompasses culture.
“Firmly in an epoch of network culture, where computational agency, intelligence, and creativity are legitimate ideas to ponder, I also want to think about its history and its politico-epistemic effects on images.”
My argument implies that computation, as a new form of mediating the world, enables a deluge of opaque image production that challenges how we can know or make sense of things. The human optical system becomes one part of a larger loop of information processing. For example, an analysis estimated that from 2022 to 2023 alone, Artificial Intelligence (AI) was used to produce 15 billion images, a figure that took photography 150 years to reach (circa 1826 until 1975).[2] The argument also implies that beyond simply facilitating this torrent, computation is responsible for the development of visual surveillance tools that enable new ways of monitoring, measuring, predicting, commodifying, and controlling individuals and large groups of people.
Jacques Rancière’s concept of the distribution of the sensible defines politics in a way that includes what Michel Foucault called the order of things, or what is symbolically representable at any given place and time. When combining the two concepts, the struggle over the methods of sensing and the process of perception establishes a relation I call political. The distribution of the sensible contains the ethical, intellectual, and political as aesthetic experiences. The aesthetic here is not about the judgment of beauty but rather the relationship between sense perception, embodiment, meaning, and social relations.
Rather than a critique, my method of analysis is more akin to what Eyal Weizman and Mathew Fuller define as investigative aesthetics. The practice of investigative aesthetics creates observable composites using various signals that include forensic, technical, material, cultural, political, and ethical evidence. Various online and offline methodologies are combined together in transdisciplinary or antidisciplinary work to render the causes of an event or the existence of an object visible.
Practitioners deploy computational methods within legal, forensic, artistic, and critical frameworks. Investigative aesthetics takes seriously the material conditions through which events occur and attempts to create a public alternative to facts presented by power-holding actors. In so doing, it also points to longer historical processes that shape events and outcomes in the present, what I think of as the archaeology of an event. Weizman and Fuller leverage the technical in the spirit of producing a commons for knowledge that resembles a multisensory, navigable architectural model. To experience and make sense of the world and to feel spurred on to imagine it differently are aesthetic experiences and require investigative practices.
“In so doing, it also
points to longer historical processes that shape events and outcomes in the
present, what I think of as the archaeology of an event.”
This method expands the aesthetic and logical limitations of a single human subject, and thus expands a collective’s ability to sense and reason. I loosely follow their concept of investigative aesthetics throughout in attempting to agnostically make sense of computational logics and practices while retaining an ethical commitment to harm reduction and the principle of freedom. My methodology includes producing an archive, constructing a theoretical framework, empirically testing through technical and artistic practices, and relying on transdisciplinary research and pedagogy. The goal of my project is to create an ongoing framework for understanding and creating computational images that is open to new information, new case studies, and new practices (evidence).
[1] Mitchell, W., Representation, in F Lentricchia & T McLaughlin (eds), Critical Terms for Literary Study, 2nd edn, University of Chicago Press, Chicago, 1995, 4.
[2] Every Pixel Journal

What gazes back?
Computational Representation or the Statistical Gaze
“I think the style would be a bit whimsical and abstract and weird, and it tends to blend things in ways you might not ask, in ways that are surprising and beautiful. It tends to use a lot of blues and oranges. It has some favorite colors and some favorite faces. If you give it a really vague instruction, it has to go to its favorites. So, we don’t know why it happens, but there’s a particular woman’s face it likes to draw — we don’t know where it comes from, from one of our 12 training datasets — but people just call it “Miss Journey.” And there’s one dude’s face, which is kind of square and imposing, and he also shows up some time, but he doesn’t have a name yet. But it’s like an artist who has their own faces and colors.”
David Holz, Midjourney founder, interview with The Verge (2022)
For us humans, the computation involved in generative AI is catalyzing a significant change in the processual truth of what an image is. The web of computational operations in this new production process forces us to re-think what the art history and photography canons call representation. Once conceived through optical concepts and materials such as a vanishing point, a photographic plate, or a camera mirror that were invented to accommodate the human eye, computation requires images to be processed as digitized data, or numerical information.
In this visual investigation, I wanted to see what would happen when a generative AI model is set off on a recursive loop in which its own outputs are iteratively fed back to it as inputs. My hunch, or hypothesis, suggested that the statistical operations of Midjourney would prompt the model to converge to the most probable averages of its dataset when left unattended by human intervention. In this experiment, I wanted to make experienceable in an exaggerated way what could become of image production if it is increasingly automated to produce what is most probable on the Internet.
The increasing presence of AI-generated images is a phenomenon that extends to mobile photography, the metaverse, and scientific observation. Content on the Internet will soon become an AI-majority artifact, which means future datasets used to train newer AI models will rely on synthetic data, creating a closed feedback system that can intensify initial conditions and biases. Researchers have already observed this process in AI-generated natural language experiments. In one experiment, they call this effect model collapse.[1] In the published paper, they include statistical evidence suggesting that recursion with AI-generated data creates a homogenization in outputs that increasingly forgets the tails of its distribution curve. In other words, outliers in the training data become lost as the model reinforces what was originally overrepresented, leading to increasing convergence and more errors. This recursive effect is a slippery slope that poses one of the more troubling aspects of automation I wanted to explore: “biased slop.”
I designed a test for this by manually setting up a recursive process on Midjourney. I fed the model’s visual outputs back in as its inputs over a series of iterations to gauge how the initial image might change and converge formally when left reproducing without my textual prompting. Midjourney offers the ability to prompt the model with a pair of images rather than words, or a combination of images and words. In the case of the former, the company states on its website and Discord channel that the model “looks at the concepts and aesthetics of each image and merges them into a novel new image.” Just how concepts or aesthetics are defined by the model can’t really be known, although learning how to steer it towards desired outcomes has created a market for what the industry calls prompt engineering.
[1] https://arxiv.org/abs/2305.17493
meta-diffusion
1, (2023). Initial reference image: Heydar Aliyev Centre by Zaha Hadid. Initial
text prompt: “an architectural structure in the shape of a tesseract in the
middle of a contemporary Middle Eastern city.” All images produced with equal
weights, default settings, v 5.1, medium stylized.
meta-diffusion
2, (2023). No initial reference image. Initial
input prompt: “an architectural structure in the shape of a tesseract in the
middle of a contemporary Middle Eastern city.” All images produced with equal
weights, default settings, v 5.1, medium stylized.
meta-diffusion
3, (2023). Initial input prompt: “a beautiful woman
in a headscarf posing for a photograph.” Did not use grids; selected face I
believed to be “darker” out of the first mostly white outputs. All images
produced with equal weights, default settings, v 5.1, medium stylized.
A New Kind Of SUBLIME?
Creative Infringement
In 2019, computation was used to compile many terabytes of data from the Event Horizon Telescope (EHT) to produce the first (synthetic) image of a black hole roughly 55 million light-years away in the center of the Messier 87 (M87) galaxy. In 2022, Sagittarius A was imaged at the center of our own Milky Way by the Event Horizon Telescope project. These achievements, and the subsequent images produced by the James Webb Telescope, mark a seminal moment in the history of images.
The first visualization of a black hole required a synchronized array of radio telescopes located across the globe, turning the world’s surface into a sort of giant planetary sensor–a theoretical aperture the size of the Earth. The web of telescopes, which are actually radio dishes, produce high fidelity information through an interferometric process called Very Long Baseline Interferometry (VLBI) that combines their individual measurements of wave interference. To model M87’s appearance, EHT ran simulations and used ray tracing to describe the gas and plasma surrounding the black hole that were parametrized with its spin and temperature values. Ray tracing describes the computational reproduction of optical effects such as light, shadows, and depth.
The massive amounts of information recorded over ten days of observation provided data that took two years to compute and process into a verifiable and reproducible image. Scholars such as Shane Denson point to the micro-temporal speed involved in mediating everyday computational images, but in the case of the black hole the process is macro-temporal, stretching over days and years.[1] This scale, both spatially and temporally, is a new capability that affords a new kind of image.
What we see, the orange circle amid a black void, is the light from the accretion disk around the shadow of the mass that is the black hole. The color choices we see are in fact arbitrarily chosen by scientists and correspond to the temperature and wave frequencies observed in the magnetic fields near the event horizon of the black hole at the center of M87. The initial blurry image has been subsequently sharpened with new algorithms and upsampling techniques and re-published.
The collaboration brought together institutions and astronomers from all over the world seeking to push the observation of quasars and black holes beyond the limits holding science back: providing a deeper understanding of space, time, and gravity fundamental to understanding the universe. The limits of knowledge and the terrifying yet affectively pleasurable feeling of confronting it through an aesthetic experience is the sublime I want to think through here. The profundity of this astronomical image, and what it verifies and confers, prompts the question of whether it stands for a new form of the sublime.
In The Critique of the Power of Judgement, Kant analyzes the conditions that enable what he calls reflective judgements of taste, most notably those accompanying the experience of the beautiful and the sublime. Formed without the logical concepts he claimed were prerequisites for understanding and cognition, judgements of taste are closer to the imagination: they arise freely and evoke delight without ends to justify their existence. There are no proofs to validate these reflective judgements. Different than the singular preferences of an individual that he calls agreeable, judgements of the beautiful and the sublime assume a universal validity, although they are subjectively felt, which bonds all humans in what Kant calls the sensus communis of taste.
The sublime transcends the limitations of expression and representation while inducing both pleasure and terror. Regarding the limits of reason referenced in the epigraph to this chapter, the sublime allows the mind to recognize its own disposition when estimating the external world. When confronted by the infinity of the sublime, we experience an aesthetic recognition of our own finitude.
For Kant, the sublime is part of his larger critical and moral project to define freedom within the edges of human reason and aesthetic experience. I want to stay with this principal, and indeed with this definition of the sublime, yet also point to Kant’s teleology of judgment as a shortcoming that effaces the indeterminacy of experience–or the contingency of experience in the world.
Fred Moten writes about Black aesthetics as a manifestation of indeterminacy and freedom from within unfreedom–in the break, in the cut, in the blur. In reference to Miles Davis’ kinetic musical improvisation and the words of Samuel Delaney alluding to Cecil Taylor and Amiri Baraka he summons the sublime as “that which is experienced as a kind of temporal distancing and the out interinanimation of disconnection…”[2] In words written about the digital art of American Artist, Moten’s lyrical exposition is worth quoting at length:
American Artist rigorously understands that this force and power, in spite of all rhetoric regarding freedom of the imagination under liberalism, which the artist is supposed to embody, has most often, and for most people, been carceral and regulative. In this regard, (black) art has never simply been a place one goes to get free; it is, rather, an experimental constraint one enters, at one’s happily necessary peril, in order to test and break freedom’s limits.[3]
It is this temporal distancing and disconnection at the edge of reason that captures the power of the (B)lack hole image.
Computation, including AI, introduces the potential to make an image that confounds our sense of representation through the indeterminacy of its making. In the words of Parisi, “the medium is given the task of transducing the unknown.”[4] Following Sylvia Wynter’s articulation of Black women as representative of chaos, or the outside of reason set against the universality of the Western Man central to the history of science, a conceptually fugitive form of the computational suggests one path away from the instrumentality of dominant technological solutionism.[5]
[1] Denson, Shane. Discorrelated Images. Duke University Press, 2020.
[2] Moten, Fred. In The Break: The Aesthetics Of The Black Radical Tradition. United States, University of Minnesota Press, 2003. 155.
[3] Moten, Fred. “American Artist.” Cura Magazine 38. 2022.
[4] Parisi, Luciana. “The Negative Aesthetic of AI.” Digital Aesthetics Workshop. 2023, Stanford Humanities Center, Stanford Humanities Center.
[5] Wynter, Sylvia. 1984. “The Ceremony Must Be Found: After Humanism.” boundary 2 12/13, no. 3/1: 19–70.

Aitor Throup is a multisdciplinary designer and artist. The image above is from Throup’s “New Object Research” apparel catalogue from 2013. Read a profile and interview with Throup I conducted here.

An artificial image. Midjourney V6 Prompt: “An editorial image of a young black male model wearing draped contemporary clothing with baggy slacks.” This prompt was blended with the first image above by Aitor Throup using /blend feature.

An artificial image. Midjourney V6 Prompt: “An editorial image of a young black male model wearing draped contemporary clothing with baggy slacks.” This prompt was blended with the first image above by Aitor Throup using /blend feature.

An artificial image. Midjourney V6 Prompt: “An editorial image of a young black male model wearing draped contemporary clothing with baggy slacks.” This prompt was blended with the first image above by Aitor Throup using /blend feature.

An artificial image. Midjourney V6 Prompt: “An editorial image of a young black male model wearing draped contemporary clothing with baggy slacks.” This prompt was blended with the first image above by Aitor Throup using /blend feature.

Where does vision begin to see?
Anatomy of an Image
What becomes of photography in a post-photographic epoch?

“Original” photograph (above), shows birds and people walking during daylight through a Barcelona city square. Taken on a Fujifilm XT20 mirrorless digital camera. Settings: Focal length and lens: 55mm with a 1/4 light diffusion filter, F Number: f/22 Exposure: 1/8 seconds ISO 200. Largely unedited output.

Proof print of original.
Image to Video via Runway ML with prompt “Birds Flying Through Public Square”
Image to Video via Runway ML with prompt “Birds Flying Through Public Square”
A series of photographs from the original scene stiched together using Runway ML’s frame interpolation tool. Track Two by Corre.

Photographic CMYK 33x66 inch large print on thick, matte paper, held on wall by clips.

JPEG format of the file with a window overlay showing the file in TXT text format.
![]()
Expanded frame of original made with Adobe Photoshop Generative Expand feature.

Expanded frame of original made with Adobe Photoshop Generative Expand feature.

iPhone screenshot of camera roll interface showing proof print of original image.

Discerning ChatGPT4’s image description and meta-cognitive capablities.
![]()
Midjourney’s /describe feature producing prompts from the print of the original digital image.
![]()
GIF of Gaussian Splat scan of large print.
Midjourney6 output of original image + text prompt: “A painting inspired by and in the style of this long exposure photograph."

Midjourney’s /describe feature producing prompts from the print of the original digital image.

GIF of Gaussian Splat scan of large print.
Midjourney6 output of original image + text prompt: “A painting inspired by and in the style of this long exposure photograph."

Is a logogram a visual syntax?
Persian Calligraphy as Image
Is calligraphy text or an image? Is a logogram a visual syntax or a phonetic one? What can a Persian AI look like?
Images produced via Runway ML’s text-to-image model finetuned on 30 images of Persian Nastaliq calligraphy and interpolated into a video. Track Behind The Sun by Odesza.
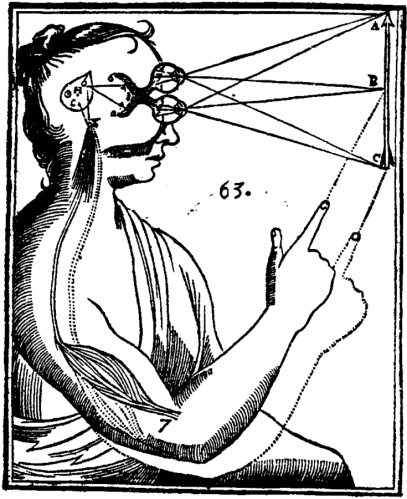
How do machines see without eyes?
An Excerpt on AI
“As nature discovered
early on, vision is one of the most powerful secret weapons of an intelligent
animal to navigate, survive, interact and change the complex world it lives in.
The same is true for intelligence systems. More than 80% of the web is data in
pixel format (photos, videos, etc.), there are more smartphones with
cameras than the number of people on earth, and every device, every machine and
every inch of our space is going to be powered by smart sensors. The only path
to build intelligent machines is to enable it with powerful visual
intelligence, just like what animals did in evolution. While many are searching
for the ‘killer app’ of vision, I’d say, vision is the ‘killer app’ of AI and
computing.”
Fei-Fei Li, interview
with TechCrunch (2017)
The shift to computation has enabled the path that leads to Artificial Intelligence. From the incipient days of the modern computer, figures like Alan Turing and Frank Rosenblatt conceived of it as a project to birth a form of intelligence. Today, the process of computational image production is increasingly automated with the help of AI. From subtle processing techniques to producing entirely synthetic images, the role of machine learning (ML) grows as a co-constructor of visuality and truth. ML is the umbrella term covering AI research that focuses on how deep neural networks learn from large datasets to produce a variety of desired (and undesired) outcomes through prediction. Since the early 2010s, ML has increasingly become the dominant form of AI research and engineering.
In 2016, DeepMind’s AlphaGo model famously defeated Lee Sedol, one of the best ever Go players in the world at the peak of his abilities. The wickedly inscrutable yet ultimately shrewd moves played by AlphaGo marked a cultural tipping point for the realization that AI and its bizarre forms of understanding had arrived. The system didn’t simply appear to win through its capability of sheer calculation of possible outcomes for each move, but rather through novel approaches and improbable decisions that defied the wisdom amassed by the masters of the art of Go over 2,000 years since its creation in ancient China.
Integral to the architecture of today’s most successful ML models are dozens of layers of artificial neural networks, designed to mimic how neurons fire and connect inside the human brain. As an input signal moves through the network during training, each node in these layers is forced to compress and learn (extract) features about its data, which it then transmits to other nodes. These transmissions, called weights, resemble synapses in the brain and are adjusted and optimized during training to guide the learning process towards desired outcomes. The weights store what, and how, the network has learned to create valuable relationships it can use to predict or generate new outputs similar to the data used to train it.
“Yet, what is this representation of data when it
is latent, emerging in high-dimensional space opaque to human comprehension?”
The most valuable connections made by the model occur in what are known as hidden layers, a latent space where models represent some correlational structure of their input data. Designed via principles of topology and vector math, the latent space, which informs the kinds of inferences and outputs any given model can make, is the epistemic space that comprises the so-called intelligence associated with machine learning. In other words, the latent space of representation is perhaps the equivalent of a world model for this new machine.

Yet, what is this representation of data when it is latent, emerging in high-dimensional space opaque to human comprehension? In decisions made by AI, the question of why is subsumed by what. One potential beauty of emerging AI is how it presents a rupture in the theory of language and logic that demand semantic meaning. [1] The abstractions mapped inside the layers of a neural network challenge and potentially transcend the requirements of human representation. Contained within them are patterns of thought that we can never consider, devoid of human comprehension. AI presents the potential for solving some intractable problems and understanding the universe deeper.

Anil Bawa-Cavia writes that there is no necessary bijection between language sets–different vocabularies do not necessarily correspond.[2] If indeed we are now confronted by a profoundly new form of inhuman intelligence we have birthed, how do we interface with it, and what are its limits? Can everything in the world be encoded and predicted probabilistically by billions of artificial neurons running on finite datasets such as the corpus of human language found on the Internet?[3] This is the expensive bet being made within much of the current market for AI. The push to reduce, or abstract, images into classifiable computational information called tokens is a part of this trend.
Katherine Hayles claims that remediation always entails translation, and that translation always entails interpretation.[4] In the process, something is lost, and something is gained. Another way to put this is that compression is almost always lossy. She dubs the encounter between older cultural practices associated with analog media and the strange flatness of digital media as intermediation. This concept feels useful in thinking about the back-and-forth transfer of knowledge between human and machine intelligence. Intermediation forces us to rethink fundamental questions such as “what is a text or an image?”.
Answers to this question can reveal surprising epistemic bias for a specific medium from a specific time and place that comes with its own historical limits. There is no convincing reason to prioritize one definition. In his approach to such a question, Jacques Derrida suggests the necessity of troubling (or putting “under erasure”) any one answer that tries to stake a definitive claim. There has never been a “genuine” or original concept of representation, only its trace. Or rather, all iterations are differences of the same essence, dependent on a set of contingent linguistic conditions.
As computing power and algorithmic sophistication expand almost overnight alongside technological demand, new subfields such as computational photography have emerged to completely restructure how we humans produce, organize, and relate to images and visual representation. Although still very much material in the sense of requiring electrical signals, energy, hardware, and human labor, the network culture that upholds computational images adds new layers of abstraction on top of previous forms of media. New logics and properties emerge that, for example, unsettle our ideas of three-dimensional Euclidean space and chronological time. A machine can hold perspectives in nearly infinite ways, while digitization can collapse past(s) and present(s) into nearly instantaneous connection. Already in the late 1980s, art historian Jonathan Crary anticipated how the technical assembly of computer graphics nullified “most of the culturally established meanings of the terms observer and representation.” [5]
[1] I view artificial intelligence as both a field of research and a technology. I define it technically as a set of programmed instructions for predictive systems that can learn to evolve beyond their initial inputs and process human-level tasks (in some common ways not as well as humans, in some complex ways exponentially more efficiently than humans).
[2] Bawa-Cavia, Anil. Arity and Abstraction. Glass-Bead. http://www.glass-bead.org/research-platform/arity-abstraction/?lang=enview. 2017.
[3] I capitalize Internet, Western, and Artificial Intelligence to denote the particular historical character of these terms that are not general categories.
[4] Hayles, N K. My Mother Was a Computer: Digital Subjects and Literary Texts. Chicago: University of Chicago Press, 2005.
[5] Crary, Jonathan Techniques of the Observer. Pg. 1
Say Hi
KEEP GOING

Image of "city lights" was produced with a prompt on Runway ML, finetuned on 15 of my own photographs, a majority of which are black and white.
A
Image Description: Meta-cognition
Screenshot of iPhone 14 camera interface picking up faces in a film photograph print taken by Reagan Louie and displayed at SF MOMA. The following screenshots are interactions with ChatGPT 4 about the contents of the image/photo to test its ability for meta-cognition.





I
Image made using Midjourney /blend feature
combining a sketch from Descartes and an image of a girl on a VR headset.
Using Live Recursion
Screenrecording while using Krea AI real time camera GenAI tool
Testing latent constistency models (LCM) that allow for rapid AI frame generation (via Stable Diffusion) on camera input, almost in real time


What is truth?
Applied Pedagogy


I constructed the above digital syllabus for teaching as part of a research fellowship over two years at Transformations of the Human funded by the Berggruen Institute and Reid Hoffman, building on my dissertation and artistic practice, where this performative site and its works were also made.